選択したエッジを延長し、その交点で頂点をマージしたいという要望が会社でありました。
ベクトルを使えば簡単に解決できそうな感じがしましたが、気になったので調査してみました。
以下ソース
コードと考え方は以下を参考にしました。
http://www.sousakuba.com/Programming/gs_two_lines_intersect.html
大変わかりやすく解説されています。
このソースでは、選択したエッジの交点を求め、近いほうの頂点をその座標へ移動するまでとなっていますが、処理の根幹としては十分かと。
うん、やっぱベクトルってべんりだなーと…。
2018年6月3日日曜日
2018年5月6日日曜日
OpenMaya:頂点処理の速度比較
以前海外の記述で見つけた記述を参考に、選択頂点で、設定値より近接している頂点の検索処理を、OpenMayaとmayaPythonで比較してみました。
処理内容はどちらも
①選択頂点の座標を取得
②openMayaのMVectorクラスを使って閾値以上近接している頂点を検索
③エラーがあればリストに格納して返す
以下ソース
mayaPython
openMaya
で、結果。
mayaPythonの結果: elapsed_time:1.26999998093[sec]
openMayaの結果: elapsed_time:0.103000164032[sec]
うーん! これだけで10倍以上の処理速度の差が。
ソースはもっと洗練できると思う。 もっと早くなるんじゃないだろか。
参考;
http://jensvhansen.com/fastest-way-to-query-vertex-position-in-maya/
https://boomrigs.com/blog/2016/1/12/how-to-get-mesh-vertex-position-through-maya-api
処理内容はどちらも
①選択頂点の座標を取得
②openMayaのMVectorクラスを使って閾値以上近接している頂点を検索
③エラーがあればリストに格納して返す
以下ソース
mayaPython
openMaya
で、結果。
mayaPythonの結果: elapsed_time:1.26999998093[sec]
openMayaの結果: elapsed_time:0.103000164032[sec]
うーん! これだけで10倍以上の処理速度の差が。
ソースはもっと洗練できると思う。 もっと早くなるんじゃないだろか。
参考;
http://jensvhansen.com/fastest-way-to-query-vertex-position-in-maya/
https://boomrigs.com/blog/2016/1/12/how-to-get-mesh-vertex-position-through-maya-api
2017年11月21日火曜日
レンダリング画像上の、あるノードのxy座標を取得する方法
レンダリング画像上の、あるノードのxy座標を取得する方法。 OpenMayaを介して、ワールド空間空間内の座標位置をカメラから計算し、画像上のxy座標を算出します。 レンダリング情報はレンダリング設定のcommon設定のresolutionから取得して計算します。
ソースまるコピ:
http://forums.cgsociety.org/archive/index.php?t-1109300.html
非常に分かりやすい記事でした。
なお、実際は知らせてみると、Photoshop画像上でx座標は正しい位置を取得しましたが、y座標の上下が逆転しました。うーん、なんだろ。
以上、備忘録メモ
2016年11月14日月曜日
blenderスクリプトメモ:ビューポートのカメラ設定を変える
Blenderスクリプトは、カメラ設定をいじるのにも、どこに情報が格納されているのか、探すのに一苦労でした。。
ひとまず、現在のウインドウの、View_3Dパネルを取得できれば、いろいろいじることができそう。
以下ソース
しかし、ビューにすべてのオブジェクトが入るようにするやり方がわからなかった。
(ショートカットだと、shift+C)
引き続き調査してみます。
ひとまず、現在のウインドウの、View_3Dパネルを取得できれば、いろいろいじることができそう。
以下ソース
しかし、ビューにすべてのオブジェクトが入るようにするやり方がわからなかった。
(ショートカットだと、shift+C)
引き続き調査してみます。
blender スクリプトメモ:fileDialogでファイルパスを取得する
Mayaのmelやpythonだと、fileDialogを出すのには全く苦労しませんが、
Blenderはかなり面倒くさかったです。
あちこち調べて、ようやくソースを見つけたので、こちらにメモします。
以下ソース
参考:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
本当は、fileDialogから、単にパスを返すだけのソースにしたかったのですが、解決方法がわからず、fileDialogを呼び出した処理の中に、本処理を書き込む流れになっています。
うーむ。。気持ち悪い。。
というか、たかだかfileDialogだすだけで相当時間を食ってしまった…南無三。
2016年10月20日木曜日
blender::スクリプトで後からActionにgroupを追加し、fcurveを登録する方法
現在、お仕事でBlenderのスクリプトを触っているのですが、まったくMayaのそれとは異質で四苦八苦。。(汗
>>> for fc in fcList:
... fc.group.name='test'
>>>for fc in fcList:
... fc.group=bpy.context.object.animation_data.action.groups['test']
※12/1修正:名前指定ではグループに入りませんでした!
※グループオブジェクトを指定する必要があるようです。
同じpythonといっても、Blenderのpythonスクリプティングは、完全にオブジェクト指向なので、コマンドを動かして操作するmaya pythonとはまったくハンドリングが違う。
たかだかジョイントツリーを選択するだけで時間がかかる…!
Blender pythonでの操作方法はいくつかわかってきましたが、そのうち一つをこちらでメモを兼ねて公開します。
通常、Blender上でアニメーションを作成すると、ArmatureにActionを登録し、キーフレームを作成すると、Actionデータの中に骨ごとのグループができて、中にfcurveが登録されます。
が、例えば、FBXなどをインポートすると、(出力やインポート方法によって異なるかもですが)、この骨ごとのグループが作成されず、Armature直下にfcurveが登録されます。
これを骨ごとのグループに登録しなおすには、ActionEditor上から手作業でグループを作成…してもよいのですが、面倒。
スクリプトでやると、以下の通りです。
※あらかじめ編集したいArmatureを選択してアクティブにしておくことが前提
※アクティブにするArmatureをスクリプトで指定する方法は、またべつのはなし(笑)
#まず、新規にActionにgroupを追加する。
>>> bpy.context.object.animation_data.action.groups.new('test')
#手動操作時の、infoウインドウにログ表示される「bpy.ops.anim.channels_group(name="testGrp")
」という入力だとなんでか怒られます。おそらく、fcurveがきちんと指定できてないのかも。
#つぎに、アニメーションカーブを取得します。
>>> fcList=bpy.context.object.animation_data.action.fcurves
#カーブごとのグループアトリビュートを指定します。
>>>for fc in fcList:
... fc.group=bpy.context.object.animation_data.action.groups['test']
※12/1修正:名前指定ではグループに入りませんでした!
※グループオブジェクトを指定する必要があるようです。
…以上!(ジェイソン風味
fcurveごとに登録したいグループを変えるのであれば、fcurveのdata_pathアトリビュートから、UI上に表示されている名前を取得できるので、if文で処理分岐するといいと考えています。
2016年7月10日日曜日
pythonでredmineを使う。
オープンソースのプロジェクト管理ソフトウェア、「redmine」ですが、
僕の環境でもredmineを使ったプロジェクト管理を模索しています。
他の会社などの話を様々なセミナーで聞くと、(redmineに限った話ではないですが)様々な環境に合わせたカスタマイズが行われているようです。
Mayaとredmineなどの管理ソフトの連動なども行われていたり。
僕の方でも、redmineをより使いやすくするため、pythonからアクセスする方法を模索してみました。
redmineにはrestAPIでアクセスが可能ですが、pythonでアクセスできれば、
デスクトップToolだけでなく、Mayaとの連動でタスク管理することが可能になってきます。
Mayaから実行する場合、MayaのpythonPathが通っているところにモジュールをおいて、importすればOK。
githubにモジュールあるので、ダウンロードして使用できます。
python-redmineからアクセスする際も、同じようにエラーが返ってきて、情報が取得できませんでした。
このSSL認証をスキップするには、…
redmine = Redmine('https://redmine.url', requests={'verify': False})
この記述で解決しました。
python-redmineに同梱されている、requestModuleのバージョンによって、
エラー表示が出まくることがありますが、とりあえず実行・情報取得はできました。
エラーを非表示にしたい場合、requestモジュールのバージョンを下げれば解決するそうです。
でもまぁ、値さえ取得できればOKなので、僕は無視してます。
参考URL
http://qiita.com/mima_ita/items/1a939db423d8ee295c85
https://github.com/maxtepkeev/python-redmine/issues/1
https://pypi.python.org/pypi/python-redmine
http://python-redmine.readthedocs.io/resources/issue_category.html#manager
僕の環境でもredmineを使ったプロジェクト管理を模索しています。
他の会社などの話を様々なセミナーで聞くと、(redmineに限った話ではないですが)様々な環境に合わせたカスタマイズが行われているようです。
Mayaとredmineなどの管理ソフトの連動なども行われていたり。
僕の方でも、redmineをより使いやすくするため、pythonからアクセスする方法を模索してみました。
redmineにはrestAPIでアクセスが可能ですが、pythonでアクセスできれば、
デスクトップToolだけでなく、Mayaとの連動でタスク管理することが可能になってきます。
・python-redmineモジュールを使う。
→これで解決しました(簡単)。 まさにそれ、というモジュールがあったのですね。。Mayaから実行する場合、MayaのpythonPathが通っているところにモジュールをおいて、importすればOK。
githubにモジュールあるので、ダウンロードして使用できます。
・ssl認証エラーする場合は?
割と壁だったのが、SSL認証。 オレオレ認証かなんかを使っていると、「このサイト信用できまへんで」などと言われてブラウザに怒られます。python-redmineからアクセスする際も、同じようにエラーが返ってきて、情報が取得できませんでした。
このSSL認証をスキップするには、…
redmine = Redmine('https://redmine.url', requests={'verify': False})
この記述で解決しました。
python-redmineに同梱されている、requestModuleのバージョンによって、
エラー表示が出まくることがありますが、とりあえず実行・情報取得はできました。
エラーを非表示にしたい場合、requestモジュールのバージョンを下げれば解決するそうです。
でもまぁ、値さえ取得できればOKなので、僕は無視してます。
参考URL
http://qiita.com/mima_ita/items/1a939db423d8ee295c85
https://github.com/maxtepkeev/python-redmine/issues/1
https://pypi.python.org/pypi/python-redmine
http://python-redmine.readthedocs.io/resources/issue_category.html#manager
2016年6月19日日曜日
文字分割は、python使ったほうが楽?
pythonでのコーディングは便利でいいですが、やはりmelにはmelの良さがあるし、melのほうが手っ取り早いこともあります。
ただ、melはやっぱりpythonと比べると、文字分割関連がめんどくさい…。
たとえば、文字列…
"aaa/bbb/ccc.bmp"
で、"bbb"を抜き出したい場合、おそらく普通にmelでコーディングすると…
string $temp[] = stringToSTringArray("aaa/bbb/ccc.bmp","/");
string $result = $temp[1] ;
など、stringToStringArrayを使わない場合でも、一度配列に出してから抜き出さないと、だと思います。
今日試してみたのが、pythonを挟む方法です。
string $result = python('aaa/bbb/ccc.bmp'.split('/')[-2]);
…一行で済むというね!
しばらくこちらを試してみようと思います。
ただ、melはやっぱりpythonと比べると、文字分割関連がめんどくさい…。
たとえば、文字列…
"aaa/bbb/ccc.bmp"
で、"bbb"を抜き出したい場合、おそらく普通にmelでコーディングすると…
string $temp[] = stringToSTringArray("aaa/bbb/ccc.bmp","/");
string $result = $temp[1] ;
など、stringToStringArrayを使わない場合でも、一度配列に出してから抜き出さないと、だと思います。
今日試してみたのが、pythonを挟む方法です。
string $result = python('aaa/bbb/ccc.bmp'.split('/')[-2]);
…一行で済むというね!
しばらくこちらを試してみようと思います。
pythonソース もう一度importするには??
melのsourdeと違って、pythonの場合、ソースを更新して再度importコマンドを行っても更新されることがありません。
この場合、reload()関数を使うと解決できます。
⇒reload関数()
ほかにも、読み込んだモジュールを削除して再度importする方法を採用している方もいるようです。
⇒.pyファイルの再import
とくにもんだいなければ、reload関数を使うのがよさそうです。
この場合、reload()関数を使うと解決できます。
⇒reload関数()
ほかにも、読み込んだモジュールを削除して再度importする方法を採用している方もいるようです。
⇒.pyファイルの再import
とくにもんだいなければ、reload関数を使うのがよさそうです。
2016年6月12日日曜日
任意のフォルダのpythonファイルをimport コマンドから持ってくる
Toolのソースを、特定のフォルダの特定階層に整理したいのに、melファイルのsourceコマンドとは違って、pythonのimportコマンドは、あらかじめpythonパスが通っているところしか見てくれない。
そういう場合は、環境変数に書き込むか、一時的リリースのToolなんかだったら、一時的にpythonパスをソースから追加することでインポートが可能です。
サンプルソース; これでpythonパスを一時的に追加できるので、この後importコマンドを走らせればいい
そういう場合は、環境変数に書き込むか、一時的リリースのToolなんかだったら、一時的にpythonパスをソースから追加することでインポートが可能です。
サンプルソース; これでpythonパスを一時的に追加できるので、この後importコマンドを走らせればいい
2016年1月5日火曜日
【Maya】 【python】ポリゴンの凹面を判別する。
少し前からですが、アーティストの方から割と要望をいただく件として、
「ポリゴンメッシュの凹面を自動判別する機能」があります。
早めに開発着手したかったのですが、なかなか手が空かず、
時間ばかりいただいてしまいました。。
で、ちょうど年末年始、数学に強い従兄の助言もいただき、
時間のあるこの時期に大体形にしてみたので、こちらでも紹介します。
■どうやって凹凸を判別するか?
チェックするポリゴンは4頂点の4角形であることが前提です。
そもそも3角形だったら平面だし。5角形だったらそもそもポリゴン割れし。
で、仕組みはこうです。
ずばり内積と外積を使います。
ベクトルの内積と外積を使って、4頂点のうち、
3頂点の平面から見た残りの1点の位置を判別します。

~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
かんたんに外積:
 2つのベクトルに垂直なベクトルを算出します。
2つのベクトルに垂直なベクトルを算出します。
かんたんに内積:
 ベクトルAをベクトルBに成分分解したときの、そのベクトルの長さを求めます。
ベクトルAをベクトルBに成分分解したときの、そのベクトルの長さを求めます。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
その手順は…、
①3頂点で作る、1点から伸びる2本のベクトルの外積を出して、
この3角形に垂直なベクトルを算出します。

②残り1頂点で作るベクトルと、①の三角形に垂直なベクトルの内積を求めます。

この内積の値が正か負かで、残りの1点の位置が算出できるはずです。
■しかし、ポリゴンのみかたで凹か凸かが変わってしまう。
この4頂点ですが…
 こうみるか
こうみるか

こうみるかで、凹か凸かが変わってしまいます。
要は、どの頂点を判別するのか、準点を定める必要があるわけです。
ここは、判別の基準をアーティストさんに確認する必要がありますが、、、
とりあえず、一度Triangulateをかけた時の形状が、凹か凸かを判別するように
考えることにしました。
要は、このポリゴンを…

Triangulateをかけて…

この3角形に含まれない頂点…

つまり、この頂点を判別することにします。

■melに便利なコマンドが
melにズバリ、内積・外積を算出するコマンドがあるので、これを使うっきゃない。
外積:cross http://download.autodesk.com/global/docs/maya2014/ja_jp/Commands/cross.html
内積:dot http://download.autodesk.com/global/docs/maya2014/ja_jp/Commands/dot.html
しかし、頂点計算など、数が多い処理は全てmelで処理するには重たすぎるので、
基本はすべてpythonで書くことにし、pythonからmelプロシージャを呼び出すようにします。
そんな感じで、ぱっと作ってみました。
※使用方法は、mel文を先に実行しておくか、sourceコマンドで読んでおいた上で
ポリゴンを選択し、python文を実行します。
すると、凹んだ角形のみが選択された状態で終了します。
実際にまだ使っていないので、信頼性は低いですが。
いろいろテストなどして、ブラッシュアップしていこうと思います。
以下ソース
「ポリゴンメッシュの凹面を自動判別する機能」があります。
早めに開発着手したかったのですが、なかなか手が空かず、
時間ばかりいただいてしまいました。。
で、ちょうど年末年始、数学に強い従兄の助言もいただき、
時間のあるこの時期に大体形にしてみたので、こちらでも紹介します。
■どうやって凹凸を判別するか?
チェックするポリゴンは4頂点の4角形であることが前提です。
そもそも3角形だったら平面だし。5角形だったらそもそもポリゴン割れし。
で、仕組みはこうです。
ずばり内積と外積を使います。
ベクトルの内積と外積を使って、4頂点のうち、
3頂点の平面から見た残りの1点の位置を判別します。

~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
かんたんに外積:
 2つのベクトルに垂直なベクトルを算出します。
2つのベクトルに垂直なベクトルを算出します。かんたんに内積:
 ベクトルAをベクトルBに成分分解したときの、そのベクトルの長さを求めます。
ベクトルAをベクトルBに成分分解したときの、そのベクトルの長さを求めます。~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
その手順は…、
①3頂点で作る、1点から伸びる2本のベクトルの外積を出して、
この3角形に垂直なベクトルを算出します。

②残り1頂点で作るベクトルと、①の三角形に垂直なベクトルの内積を求めます。

この内積の値が正か負かで、残りの1点の位置が算出できるはずです。
■しかし、ポリゴンのみかたで凹か凸かが変わってしまう。
この4頂点ですが…
 こうみるか
こうみるか
こうみるかで、凹か凸かが変わってしまいます。
要は、どの頂点を判別するのか、準点を定める必要があるわけです。
ここは、判別の基準をアーティストさんに確認する必要がありますが、、、
とりあえず、一度Triangulateをかけた時の形状が、凹か凸かを判別するように
考えることにしました。
要は、このポリゴンを…

Triangulateをかけて…

この3角形に含まれない頂点…
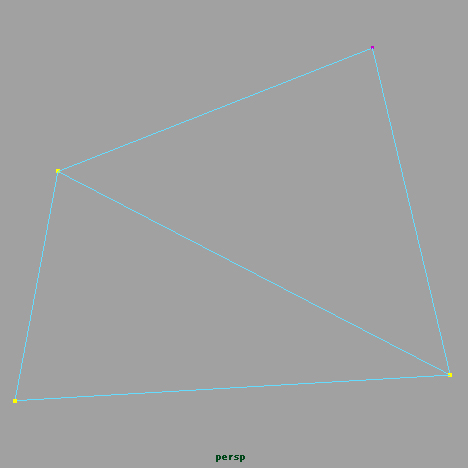
つまり、この頂点を判別することにします。

■melに便利なコマンドが
melにズバリ、内積・外積を算出するコマンドがあるので、これを使うっきゃない。
外積:cross http://download.autodesk.com/global/docs/maya2014/ja_jp/Commands/cross.html
内積:dot http://download.autodesk.com/global/docs/maya2014/ja_jp/Commands/dot.html
しかし、頂点計算など、数が多い処理は全てmelで処理するには重たすぎるので、
基本はすべてpythonで書くことにし、pythonからmelプロシージャを呼び出すようにします。
そんな感じで、ぱっと作ってみました。
※使用方法は、mel文を先に実行しておくか、sourceコマンドで読んでおいた上で
ポリゴンを選択し、python文を実行します。
すると、凹んだ角形のみが選択された状態で終了します。
実際にまだ使っていないので、信頼性は低いですが。
いろいろテストなどして、ブラッシュアップしていこうと思います。
以下ソース
2015年5月3日日曜日
スキンウエイト値を切り捨て・切り上げ・四捨五入するプロシージャ
引き続き、モデラーさん用Toolを作成してます。
表題のような機能を持ったToolの作成依頼があったので、対応してました。
最初melで処理を作ったのですが、頂点数が多いと途端に重たくなり、
えっなに、フリーズ!?...みたいな状態。。。せいぜい2000頂点とかその程度で
重たくなりました。
パイソン…やるか。。
というわけで、今回はpythonのお話です。
どっちにせよ、ゆくゆく.pyは習得するつもりで、チマチマ勉強はしていたので、
ついに日の目を見る時が来たか。。。という感じで、練習&実習がてら.pyでプロシージャを
組んでみました。
以下ソースです。
mode=1で切り捨て・mode=2で切り上げ・mode=3で四捨五入。
CUL_floatは、切り上げ・切り下げの目安の数値 ※四捨五入モードでは無視されます。
CUL_ROUNDは、小数点第何位かの指定、です。
例)
mode=1,CUL_float=2.0,CUL_ROUND=2.0で、0.02で切り上げ
mode=2,CUL_float=2.0,CUL_ROUND=1.0で、0.2で切り上げ
mode=3,CUL_float=5.0,CUL_ROUND=2.0で、0.05で切り上げ
import maya.cmds as mc
import maya.mel as mel
import math as math
def ARKW_skinWeightAdjustProc(mode=0,CUL_float=2.0,CUL_ROUND=2.0):
skincluster=[]
vtx_list=mc.ls(sl=True,fl=True)
#頂点ごとの処理
for vtx in vtx_list:
inflnode_list=[]
inflpct_list=[]
new_inflpct_list=[]
node_name=vtx.split('.')[0]
#スキンクラスタを探す
skincluster=mel.eval('findRelatedSkinCluster %s'%node_name)
#スキンクラスタがなければスキップ
if skincluster is None:
mc.error('スキンクラスタが見当たりません。\n',sl=False)
else:
#インフルエンスオブジェクトのリストを取得する
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t=None)
#インフルエンスオブジェクトごとにスキン数値の取得
for inflnode in inflnode_list:
inflpct_list.append(mc.skinPercent(skincluster,vtx,t=inflnode,q=True))
i=0
while(i<len(inflpct_list)):
#切り捨て
if mode==0:
inflpct_list[i] = math.floor(inflpct_list[i]*10.0**CUL_ROUND)
REM = inflpct_list[i]%CUL_float
QUO = math.floor(inflpct_list[i]/CUL_float)
if REM>0:
inflpct_list[i] = CUL_float*QUO
inflpct_list[i] *= 1/10.0**CUL_ROUND
#切り上げ
elif mode==1:
inflpct_list[i] = math.ceil(inflpct_list[i]*10.0**CUL_ROUND)
REM = inflpct_list[i]%CUL_float
QUO = math.floor(inflpct_list[i]/CUL_float)
if REM>0:
inflpct_list[i] = CUL_float*QUO+CUL_float
inflpct_list[i] *= 1/10.0**CUL_ROUND
#四捨五入
else:
inflpct_list[i] = round(inflpct_list[i],int(CUL_ROUND))
i+=1
#値の正規化
i=0
j=0
while(i<len(inflpct_list)-1):
if inflpct_list[i]<inflpct_list[i+1]:
j=i
elif inflpct_list[i]>inflpct_list[i+1]:
j=i+1
i+=1
total_skinpct=0.0
i=0
while(i<len(inflpct_list)):
total_skinpct=total_skinpct+inflpct_list[i]
i+=1
if total_skinpct!=1:
inflpct_list[j] += 1-total_skinpct
#スキンウエイトの適応
mc.setAttr((skincluster + '.normalizeWeights'),0)
i=0
while (i<len(inflnode_list)):
mc.skinPercent(skincluster,vtx,nrm=False,tv=(inflnode_list[i],inflpct_list[i]))
i+=1
mc.setAttr((skincluster + '.normalizeWeights'),1)
#print (inflpct_list)
del inflnode_list
del inflpct_list
---------------
今回、慣れない.pyだったので、いろいろ苦労しましたが、
ポイントは3点ほどありました。
①melにしかないコマンドは、pythonからmelを呼ぶ
#スキンクラスタを探す
skincluster=mel.eval('findRelatedSkinCluster %s'%node_name)
↑ここですね。
②skinPercentコマンドで、transformをqモードで呼び出したいときはNoneで指定する
#インフルエンスオブジェクトのリストを取得する
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t=None)
↑これですね。。。
ここは結構詰まりました。
melでの書き方では…
string $inflnode_list[]=`skincluster -q -t skincluster vtx`;
…ですので、最初は、
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t=True)
とか
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t='')
とか
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t=)
とか、試しましたが、すべて怒られましたw
t=None と指定しないといけなかったのですね!
参考:http://forums.cgsociety.org/archive/index.php/t-928526.html
調べたら、割と結構同じ個所で悩まれた方がいるみたいで。。
てっとり早くmelから呼び出して解決された方なんかもいらっしゃるみたいですね。。。
③ceil/floorしたfloat数値をリストに入れ、そのまま照会すると、ceil/floorされてない!
これも。。。悩みました。
たとえば、
d_list=[]
a=0.4966666
b=100.0
c=math.floor(a*b)
d_list.append(c/b)
print (d_list)
print (d_list[0])
・・・を実行すると、
[0.48999999999999999]
0.49
・・・という結果が返ってきます。
リストに入れたままprintすると、近似値が返ってくるんですね。。。
ちゃんと数値を扱いたい場合は、取り出してあげないといけないのかな??
pythonのドキュメントを呼んでいたところ、
「Python は格納されている値の10進小数での近似値を表示するので、格納されている値が元の10進小数の近似値でしか無いことを忘れがちです。」http://docs.python.jp/2/tutorial/floatingpoint.html
・・・との表記が。
これは仕様なのかな。。
ともあれ、なんとか形にできそう。
Pythonは、文法自体はすごくわかりやすいし、いろいろてっとり早かったりするので、
慣れると作業が速くなるかもしれません。処理も早くなるし、APIにもアクセスできるし、
他にもいろいろなモジュールがあるから、便利だし。。。
pythonはいいことづくしという感じでしょうか。
python開発の、よい一歩になりました。
表題のような機能を持ったToolの作成依頼があったので、対応してました。
最初melで処理を作ったのですが、頂点数が多いと途端に重たくなり、
えっなに、フリーズ!?...みたいな状態。。。せいぜい2000頂点とかその程度で
重たくなりました。
パイソン…やるか。。
というわけで、今回はpythonのお話です。
どっちにせよ、ゆくゆく.pyは習得するつもりで、チマチマ勉強はしていたので、
ついに日の目を見る時が来たか。。。という感じで、練習&実習がてら.pyでプロシージャを
組んでみました。
以下ソースです。
mode=1で切り捨て・mode=2で切り上げ・mode=3で四捨五入。
CUL_floatは、切り上げ・切り下げの目安の数値 ※四捨五入モードでは無視されます。
CUL_ROUNDは、小数点第何位かの指定、です。
例)
mode=1,CUL_float=2.0,CUL_ROUND=2.0で、0.02で切り上げ
mode=2,CUL_float=2.0,CUL_ROUND=1.0で、0.2で切り上げ
mode=3,CUL_float=5.0,CUL_ROUND=2.0で、0.05で切り上げ
import maya.cmds as mc
import maya.mel as mel
import math as math
def ARKW_skinWeightAdjustProc(mode=0,CUL_float=2.0,CUL_ROUND=2.0):
skincluster=[]
vtx_list=mc.ls(sl=True,fl=True)
#頂点ごとの処理
for vtx in vtx_list:
inflnode_list=[]
inflpct_list=[]
new_inflpct_list=[]
node_name=vtx.split('.')[0]
#スキンクラスタを探す
skincluster=mel.eval('findRelatedSkinCluster %s'%node_name)
#スキンクラスタがなければスキップ
if skincluster is None:
mc.error('スキンクラスタが見当たりません。\n',sl=False)
else:
#インフルエンスオブジェクトのリストを取得する
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t=None)
#インフルエンスオブジェクトごとにスキン数値の取得
for inflnode in inflnode_list:
inflpct_list.append(mc.skinPercent(skincluster,vtx,t=inflnode,q=True))
i=0
while(i<len(inflpct_list)):
#切り捨て
if mode==0:
inflpct_list[i] = math.floor(inflpct_list[i]*10.0**CUL_ROUND)
REM = inflpct_list[i]%CUL_float
QUO = math.floor(inflpct_list[i]/CUL_float)
if REM>0:
inflpct_list[i] = CUL_float*QUO
inflpct_list[i] *= 1/10.0**CUL_ROUND
#切り上げ
elif mode==1:
inflpct_list[i] = math.ceil(inflpct_list[i]*10.0**CUL_ROUND)
REM = inflpct_list[i]%CUL_float
QUO = math.floor(inflpct_list[i]/CUL_float)
if REM>0:
inflpct_list[i] = CUL_float*QUO+CUL_float
inflpct_list[i] *= 1/10.0**CUL_ROUND
#四捨五入
else:
inflpct_list[i] = round(inflpct_list[i],int(CUL_ROUND))
i+=1
#値の正規化
i=0
j=0
while(i<len(inflpct_list)-1):
if inflpct_list[i]<inflpct_list[i+1]:
j=i
elif inflpct_list[i]>inflpct_list[i+1]:
j=i+1
i+=1
total_skinpct=0.0
i=0
while(i<len(inflpct_list)):
total_skinpct=total_skinpct+inflpct_list[i]
i+=1
if total_skinpct!=1:
inflpct_list[j] += 1-total_skinpct
#スキンウエイトの適応
mc.setAttr((skincluster + '.normalizeWeights'),0)
i=0
while (i<len(inflnode_list)):
mc.skinPercent(skincluster,vtx,nrm=False,tv=(inflnode_list[i],inflpct_list[i]))
i+=1
mc.setAttr((skincluster + '.normalizeWeights'),1)
#print (inflpct_list)
del inflnode_list
del inflpct_list
---------------
今回、慣れない.pyだったので、いろいろ苦労しましたが、
ポイントは3点ほどありました。
①melにしかないコマンドは、pythonからmelを呼ぶ
#スキンクラスタを探す
skincluster=mel.eval('findRelatedSkinCluster %s'%node_name)
↑ここですね。
②skinPercentコマンドで、transformをqモードで呼び出したいときはNoneで指定する
#インフルエンスオブジェクトのリストを取得する
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t=None)
↑これですね。。。
ここは結構詰まりました。
melでの書き方では…
string $inflnode_list[]=`skincluster -q -t skincluster vtx`;
…ですので、最初は、
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t=True)
とか
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t='')
とか
inflnode_list=mc.skinPercent(skincluster,vtx,q=True,t=)
とか、試しましたが、すべて怒られましたw
t=None と指定しないといけなかったのですね!
参考:http://forums.cgsociety.org/archive/index.php/t-928526.html
調べたら、割と結構同じ個所で悩まれた方がいるみたいで。。
てっとり早くmelから呼び出して解決された方なんかもいらっしゃるみたいですね。。。
③ceil/floorしたfloat数値をリストに入れ、そのまま照会すると、ceil/floorされてない!
これも。。。悩みました。
たとえば、
d_list=[]
a=0.4966666
b=100.0
c=math.floor(a*b)
d_list.append(c/b)
print (d_list)
print (d_list[0])
・・・を実行すると、
[0.48999999999999999]
0.49
・・・という結果が返ってきます。
リストに入れたままprintすると、近似値が返ってくるんですね。。。
ちゃんと数値を扱いたい場合は、取り出してあげないといけないのかな??
pythonのドキュメントを呼んでいたところ、
「Python は格納されている値の10進小数での近似値を表示するので、格納されている値が元の10進小数の近似値でしか無いことを忘れがちです。」http://docs.python.jp/2/tutorial/floatingpoint.html
・・・との表記が。
これは仕様なのかな。。
ともあれ、なんとか形にできそう。
Pythonは、文法自体はすごくわかりやすいし、いろいろてっとり早かったりするので、
慣れると作業が速くなるかもしれません。処理も早くなるし、APIにもアクセスできるし、
他にもいろいろなモジュールがあるから、便利だし。。。
pythonはいいことづくしという感じでしょうか。
python開発の、よい一歩になりました。
登録:
投稿 (Atom)